|
Dear Reader,
Announcements
Ready to level up your understanding of AI agents? 🤖
We all see the impressive capabilities of tools like Claude Code, Open Clawd, and Hermes, but what actually powers them behind the scenes?
In our latest Substack post, we break down the "secret sauce" of modern AI assistants by walking through how to build a basic agentic harness. If you're building with LLMs, exploring agentic workflows, or just want to understand the infrastructure that makes these tools tick, this is a must-read!
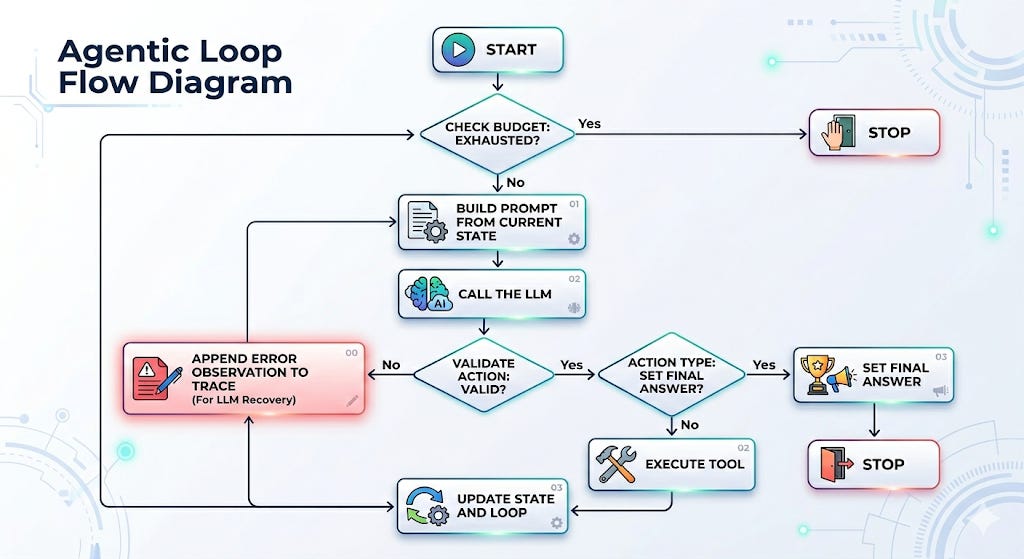
Check it out and Subscribe so you don't miss another post.
This week’s lineup pulls together a few threads worth following. Anthropic researchers looked at how large language models handle emotion concepts, tracing the internal representations that shape tone, refusals, and social reasoning. The findings push back on the idea that models simply pattern-match feelings, and raise harder questions about what these representations are doing inside the network. Paired with that, a piece on AI progress creating more work for humans makes a counterintuitive case: faster generation means more review, more verification, more cleanup. The productivity story turns out to be messier than the marketing decks suggest.
On the technical side, a write-up on Distribution Fine Tuning offers a practical method for taming the bland, overly polished prose that most fine-tuned models produce. The author treats writing quality as a distribution-matching problem and shows results that read more like a person and less like a template. For readers who want a deeper foundation, a guide to harness engineering walks through the scaffolding behind serious model evaluation, which is a topic that gets less attention than benchmarks but matters more for real deployments. Two other pieces round things out nicely: a look at the science of unpredictability from Los Alamos, and a fresh reading of what Gödel’s incompleteness theorems actually claim, which is rarely what people think they claim.
On the research side, a few papers stand out. One team showed that large language models can be used for large-scale online deanonymization, pulling identifying details out of pseudonymous posts at a scale that raises real privacy concerns. The pipeline works on ordinary public text, which is the part that should worry people. A related line of work demonstrates how persuasion techniques borrowed from social psychology can pressure models into complying with requests they would otherwise refuse. Commitment, authority, and reciprocity all transfer surprisingly well from human targets to model targets. Another paper digs into the social side of model behavior and finds that sycophantic AI decreases prosocial intentions and nudges users toward dependence, which complicates the usual framing of helpfulness as a pure good.
A few more technical pieces are worth a look. Researchers proposed multi-stream language models that run parallel streams of thought, input, and output, which loosens the single-track bottleneck most current systems sit in. Work on steered LLM activations shows that activation steering is non-surjective, meaning some target behaviors simply cannot be reached by nudging hidden states, no matter how hard you push. That result has real consequences for interpretability and control. For readers who want background theory, a set of lecture notes on statistical physics and neural networks connects spin glasses, learning dynamics, and modern architectures in a clean format. And on the applied front, a broad review of global approaches to infectious disease surveillance and modeling lays out how data pipelines, genomic sequencing, and statistical models now work together during outbreaks, with lessons that carry over to other high-stakes forecasting domains.
Our current book recommendation is "LLMs in Production: From Language Models to Successful Products" by C. Brousseau and M. Sharp. In this week's video, we have a discussion on Harness Engineering: How to Build Software When Humans Steer, Agents Execute by Ryan Lopopolo from OpenAI.
Data shows that the best way for a newsletter to grow is by word of mouth, so if you think one of your friends or colleagues would enjoy this newsletter, go ahead and forward this email to them. This will help us spread the word!
Semper discentes,
The D4S Team
"LLMs in Production: From Language Models to Successful Products" by C. Brousseau and M. Sharp is for data scientists and machine learning engineers who have moved past the “cool demo” phase and now need to ship something people can use. The book focuses on the real work behind LLM products: choosing models, preparing data, building RAG systems, evaluating outputs, controlling cost, managing latency, and deploying reliably.
Its biggest strength is that it treats LLMs as production software, not magic. The authors connect familiar ML concerns—measurement, data quality, feedback loops, monitoring, and trade-offs—to newer LLM-specific patterns such as prompt design, fine-tuning, LoRA, RLHF, hosted APIs, Kubernetes deployment, and edge inference. The hands-on projects help ground the material, especially for readers who want more than another conceptual overview.
The book is not perfect. Some sections move quickly, and experienced MLOps engineers may wish for more depth on architecture, observability, or failure analysis. Its tooling choices may also date quickly, as LLM infrastructure continues to shift. Still, the core value holds: this is a practical guide to thinking like an engineer when working with language models. For anyone trying to turn LLM experiments into durable products, it is an easy book to justify buying.
- Emotion concepts and their function in a large language model [anthropic.com]
- The Science of Unpredictability [lanl.gov]
- AI progress creates more work for humans, not less [every.to]
- What Do Gödel’s Incompleteness Theorems Truly Mean? [quantamagazine.org]
- Fixing LLM writing with Distribution Fine Tuning [rosmine.ai]
- Learn Harness Engineering [walkinglabs.github.io]
- Project Glasswing: what Mythos showed us [blog.cloudflare.com]
-
Large-scale online deanonymization with LLMs (S. Lermen, D. Paleka, J. Swanson, M. Aerni, N. Carlini, F. Tramèr)
-
Lecture Notes on Statistical Physics and Neural Networks (O. Hohm)
-
Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs (G. Su, Y. Yang, X. Li, J. Geiping)
- Sycophantic AI decreases prosocial intentions and promotes dependence (M. Cheng, C. Lee, P. Khadpe, S. Yu, D. Han, D. Jurafsky)
- Global approaches to infectious disease surveillance and modeling (M. P. Khurana, J. L.-H. Tsui, B. Gutierrez, A. Chopra, N. Scheidwasser, H. B. H. Zhu, S. Y. Chang, D. A. Duchêne, C. Mills, R. P. D. Inward, B. Reddy, J. Brittain, A. Dasgupta, J. Sheldon, G. Githinji, J. S. Brownstein, M. Monod, L. Ferretti, S. Bershan, S. Tietze, L. Ferres, S. Argimón, T. J. Dallman, E. Koua, O. Ratmann, S. Cauchemez, L. A. Meyers, L. Su, A. Vespignani, P. Pronyk, Á. O’Toole, A. Rambaut, N. J. Loman, E. C. Holmes, S. Flaxman, N. Mulder, O. W. Morgan, H. Tegally, M. Gomez-Rodriguez, N. Shadbolt, C. Happi, M. Chand, S. K. Tessema, P. Mbala-Kingebeni, M. A. Suchard, O. G. Pybus, S. V. Scarpino, S. Bhatt, M. U. G. Kraemer)
- Persuading large language models to comply with objectionable requests (L. Meincke, D. Shapiro, A. L. Duckworth, E. Mollick, L. Mollick, C. Van den Bulte, R. Cialdini)
-
Steered LLM Activations are Non-Surjective (A. Mishra, D. Khashabi, A. Liu)
Harness Engineering: How to Build Software When Humans Steer, Agents Execute
 All the videos of the week are available in our YouTube playlist.
Upcoming Events:
Opportunities to learn from us
On-Demand Videos:
Long-form tutorials
- Natural Language Processing 7h, covering basic and advanced techniques using NTLK and PyTorch.
- Python Data Visualization 7h, covering basic and advanced visualization with matplotlib, ipywidgets, seaborn, plotly, and bokeh.
- Times Series Analysis for Everyone 6h, covering data pre-processing, visualization, ARIMA, ARCH, and Deep Learning models.
|
|
|