|
Dear Reader,
Announcements
Ready to level up your understanding of AI agents? 🤖
We all see the impressive capabilities of tools like Claude Code, Open Clawd, and Hermes, but what actually powers them behind the scenes?
In our latest Substack post, we break down the "secret sauce" of modern AI assistants by walking through how to build a basic agentic harness. If you're building with LLMs, exploring agentic workflows, or just want to understand the infrastructure that makes these tools tick, this is a must-read!
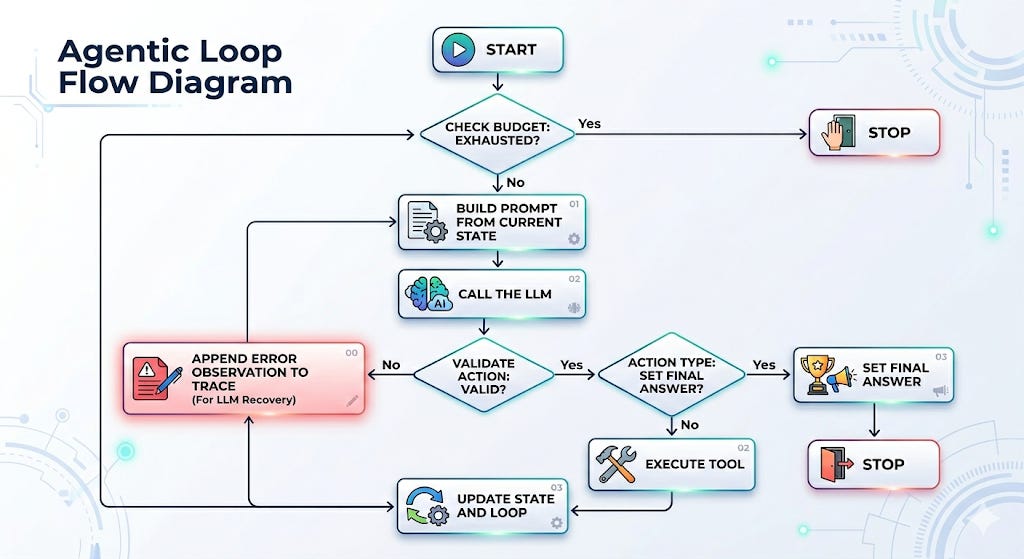
Check it out and Subscribe so you don't miss another post.
This week brings two strong learning resources for builders. A full Stanford course walks through language modeling from scratch, covering tokenization, model architecture, training, and evaluation. Students write real code and train small models step by step, not just read about them. For a hands-on security track, one developer turned personal study notes into a structured course based on Linux Basics for Hackers. Both fit readers who learn by doing.
Two pieces look at the harder side of adoption. Big companies now ration AI access as monthly bills climb faster than planned. Some teams cap tokens, cut seats, or pause projects to keep spend in check. A separate report finds that safety controls on certain Meta and Google models can be stripped in minutes. That result raises sharp questions about how well today’s guardrails actually hold.
On the research side, a new experimental model from Google DeepMind builds text with diffusion instead of standard next-token prediction. Early numbers point to very fast generation and a fresh way to think about how text models work. That speed theme returns in a short post on prototyping in the age of AI, which argues that one person can now build and test an idea in hours rather than weeks. Read together, the three links sketch a field moving fast on both methods and tools.
On the academic front, we have two papers that test how far AI agents can push real research. One team built a system where many agents work like a decentralized lab. They form teams around promising ideas, critique each other before spending compute, and share both wins and dead ends, so the group avoids repeating work. On a 24-task biomedical benchmark it reached the 74th percentile, beating the strongest prior agent by more than 8 points. A second project aimed language models at unsolved math, asking them to write proofs in Lean, a language that checks every step. The strongest agent resolved 9 of 353 open Erdős problems at a few hundred dollars each and proved 44 of 492 sequence conjectures, with the work now feeding research in graph theory, optimization, and algebraic geometry.
Other work looked at how people connect. Researchers mapped follower ties across more than 1.6 million U.S. voters on Twitter, drawn from daily samples between 2014 and 2017. Physical distance turned out to be the strongest predictor of who follows whom, ahead of age and race, with party affiliation playing a surprisingly small role. Living near someone, the data show, pulls people toward following others of the same background. So online attention still tracks the map more than the ballot box.
A field study carried that question to one of the harshest places on Earth. For ten months, twelve crew members at Antarctica’s Concordia Station wore proximity sensors. They worked through the polar winter, when the base sits cut off and temperatures drop past minus 80 Celsius. The team expected close contact to build support. The opposite happened. Frequent physical proximity lined up with more conflict, more mistrust, and lower perceived performance, and the multicultural crew slowly split into national subgroups. The result matters for long missions to the Moon and Mars, where small teams will live packed together for years.
Our current book recommendation is "LLMs in Production: From Language Models to Successful Products" by C. Brousseau and M. Sharp. In this week's video, we have a keynote by M. Ceglowski on Superintelligence: The Idea That Eats Smart People.
Data shows that the best way for a newsletter to grow is by word of mouth, so if you think one of your friends or colleagues would enjoy this newsletter, go ahead and forward this email to them. This will help us spread the word!
Semper discentes,
The D4S Team
"LLMs in Production: From Language Models to Successful Products" by C. Brousseau and M. Sharp is for data scientists and machine learning engineers who have moved past the “cool demo” phase and now need to ship something people can use. The book focuses on the real work behind LLM products: choosing models, preparing data, building RAG systems, evaluating outputs, controlling cost, managing latency, and deploying reliably.
Its biggest strength is that it treats LLMs as production software, not magic. The authors connect familiar ML concerns—measurement, data quality, feedback loops, monitoring, and trade-offs—to newer LLM-specific patterns such as prompt design, fine-tuning, LoRA, RLHF, hosted APIs, Kubernetes deployment, and edge inference. The hands-on projects help ground the material, especially for readers who want more than another conceptual overview.
The book is not perfect. Some sections move quickly, and experienced MLOps engineers may wish for more depth on architecture, observability, or failure analysis. Its tooling choices may also date quickly, as LLM infrastructure continues to shift. Still, the core value holds: this is a practical guide to thinking like an engineer when working with language models. For anyone trying to turn LLM experiments into durable products, it is an easy book to justify buying.
- Language Modeling from Scratch [cs336.stanford.edu]
- Corporate America Is Starting to Ration AI as Cost Skyrockets [wsj.com]
- Gemini Diffusion: Google DeepMind’s experimental research model [blog.google]
- Why I Made a Journal for AI-Generated Papers [cesarhidalgo.com]
- AI guardrails stripped from Meta and Google models in minutes [ft.com]
- The Speed of Prototyping in the Age of AI [darylcecile.net]
- A structured course built from personal study notes of the book Linux Basics for Hackers [github.com/ahegazy0]
-
Who Follows Whom? The Role of Geography and Similarity in Online Attention Networks (A. Quintana-Mathé, Z. Guo, N. Grinberg, D. Lazer)
- Integrating behavioural experimental findings into dynamical models to inform social change interventions (R. Tănase, R. Algesheimer, M. S. Mariani )
- AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation (S. Gao, A. Fang, M. Zitnik)
- Social interactions in isolated, confined, and extreme environments: A study of Antarctic winter teams using wearable sensors (A. Cantisani, J. B. Schmutz, P. Marques-Quinteiro, L. Dall’Amico, C. Cattuto, M. Antino, W. J. Eppich, K. Stegmayer, S. Walther)
-
Epicure: Navigating the Emergent Geometry of Food Ingredient Embeddings (J. Radzikowski, J. Chen)
-
Early warning signals for percolation transitions in networks (A. V. Goltsev, S. N. Dorogovtsev)
- Advancing Mathematics Research with AI-Driven Formal Proof Search (G. Tsoukalas, A. Kovsharov, S. Shirobokov, A. Surina, M. Firsching, G. Bérczi, F. J. R. Ruiz, A. Suggala, A. Z. Wagner, E. Wieser, L. Yu, A. Huang, M. Z. Horváth, A. Ferrauiolo, H. Michalewski, C. Grosu, T. Hubert, M. Balog, P. Kohli, S. Chaudhuri)
Superintelligence: The Idea That Eats Smart People
 All the videos of the week are available in our YouTube playlist.
Upcoming Events:
Opportunities to learn from us
On-Demand Videos:
Long-form tutorials
- Natural Language Processing 7h, covering basic and advanced techniques using NTLK and PyTorch.
- Python Data Visualization 7h, covering basic and advanced visualization with matplotlib, ipywidgets, seaborn, plotly, and bokeh.
- Times Series Analysis for Everyone 6h, covering data pre-processing, visualization, ARIMA, ARCH, and Deep Learning models.
|
|
|
