|
Dear Reader,
Announcements
✈️ Mapping the skies: How do we visualize airline traffic between states?
We often think of air travel in terms of airports, but viewing it as a network of state-to-state connections reveals fascinating patterns in how our country moves.
Our latest substack uses data visualization to turn raw statistics into a clear story about infrastructure and mobility.
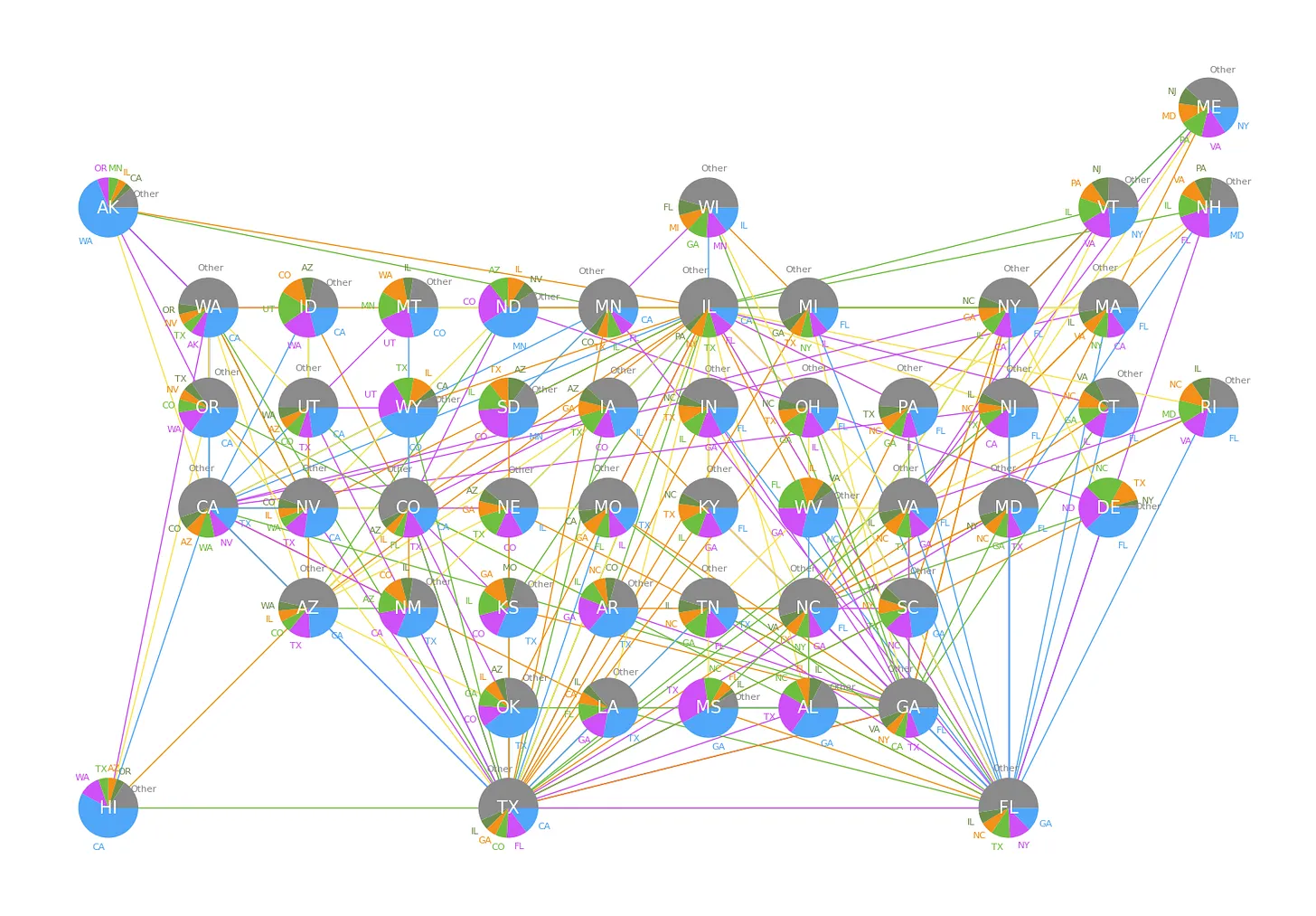
Check it out and Subscribe so you don't miss another post.
This week, we explore the recent shift in how people are thinking about modern ML and developer tooling. One piece revisits skiplists not as textbook curiosities but as practical machinery for fast search and indexing, while another makes the hidden economics of model use painfully concrete by showing how tokenizer changes can quietly inflate costs beyond the official range.
Elsewhere, there is a welcome push toward deeper technical literacy, with a clear walkthrough of spherical harmonics that reminds readers how much real math still sits underneath graphics and simulation work. On the model side, the open release of a coding-focused agentic system and a hands-on test of running a strong local model inside a coding workflow both point to the same trend: capable AI coding assistants are becoming more open, more portable, and more usable outside the biggest closed platforms.
Tying it all together is a sharp argument that the real problem with “slop” is not who wrote the first draft, but whether anyone took responsibility for reading, editing, and standing behind it, a standard that feels especially relevant now that tool calling, interface fragmentation, and open-model interoperability are becoming core engineering concerns rather than side quests.
On the academic front, we paint a picture of where AI and scientific understanding are converging, and where they still resist simplification. Work on infectious-disease forecasting and temporal networks shows just how much prediction depends on the structure of time itself: some outbreaks may be harder to foresee not because our models are weak, but because the underlying dynamics are noisier, more seasonal, or less legible than we would like.
That uncertainty echoes in the renewed scrutiny of replicability in the social and behavioral sciences, where the challenge is not just generating results, but producing findings sturdy enough to survive contact with the real world. Against that backdrop, several papers push on AI’s expanding role as an intellectual and engineering partner, from mapping the design space of code agents to imagining systems that can sustain long-horizon ML research with less human hand-holding. But the most provocative and philosophical pieces refuse to let capability masquerade as comprehension: one argues that simulation is not the same as consciousness, while another asks what, exactly, we are addressing when we “talk” to a language model in the first place.
Our current book recommendation is "Designing Data-Intensive Applications" by M. Kleppmann and C. Riccomini. You can find all the previous book reviews on our website. In this week's video, we have a lecture titled "How We Build Effective Agents" by Barry Zhang of Anthropic.
Data shows that the best way for a newsletter to grow is by word of mouth, so if you think one of your friends or colleagues would enjoy this newsletter, go ahead and forward this email to them. This will help us spread the word!
Semper discentes,
The D4S Team
"Designing Data-Intensive Applications" by M. Kleppmann and C. Riccomini is the kind of book that quietly raises the level of everyone who reads it. In this new edition, the authors do an outstanding job of explaining the core ideas behind modern data systems, like replication, consistency, storage, streaming, fault tolerance, and scalability, without reducing them to buzzwords or vendor-specific recipes. That makes the book especially valuable for data scientists and machine learning engineers as it bridges the gap between building models and understanding the data infrastructure those models depend on in production.
What makes the book so compelling is its focus on first principles. Rather than teaching a single stack or a fleeting set of tools, it gives readers a durable framework for thinking about trade-offs in real systems. That is incredibly useful for ML engineers working on pipelines, model serving, retrieval systems, or any workflow where reliability and performance matter as much as model quality. The downside is that it is more conceptual than hands-on, and readers looking for quick code examples or direct coverage of topics like feature stores, vector databases, or modern LLM infrastructure may wish it connected the dots more explicitly.
Still, that broader systems lens is exactly why the book stands out. It is thoughtful, clear, and deeply practical in the ways that matter over the long run. For anyone in data science or machine learning who wants to understand not just how to build models, but how to build the systems that let those models survive contact with reality, this is an easy book to recommend.
- What are skiplists good for? [antithesis.com]
- I Measured Claude 4.7's New Tokenizer. Here's What It Costs You. [claudecodecamp.com]
- Introduction to Spherical Harmonics for Graphics Programmers [gpfault.net]
- Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All [qwen.ai]
- Slop is text you haven't read, not text you haven't written [dwyer.co.za]
- Tool calling, open source, and the M×N problem [thetypicalset.com]
- I ran Gemma 4 as a local model in Codex CLI [medium.com/google-cloud]
-
Forecastability of infectious disease time series: are some seasons and pathogens intrinsically more difficult to forecast? (L. A. White, T. M. León)
-
Investigating the replicability of the social and behavioural sciences (A. H. Tyner, A. L. Abatayo, M. Daley, S. Field, N. Fox, N. A. Haber, K. M. Hahn, M. K. Struhl, B. Mawhinney, O. Miske, P. Silverstein, C. K. Soderberg, T. Stankov, A. Abbasi, C. L. Aberson, B. Aczel, M. Adamkovič, N. Albayrak, P. J. Allen, M. Andreychik, E. Awtrey, E. Axxe, F. Azevedo, M. D. Bader, et al)
- Maximum entropy temporal networks (P. Barucca)
-
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems (J. Liu, X. Zhao, X. Shang, Z. Shen)
-
Toward Autonomous Long-Horizon Engineering for ML Research (Guoxin Chen, Jie Chen, Lei Chen, Jiale Zhao, Fanzhe Meng, Wayne Xin Zhao, Ruihua Song, Cheng Chen, J.-R. Wen, K. Jia)
- The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness (A. Lerchner)
- What we talk to when we talk to language models (D. J. Chalmers)
How We Build Effective Agents
 All the videos of the week are now available in our YouTube playlist.
Upcoming Events:
Opportunities to learn from us
On-Demand Videos:
Long-form tutorials
- Natural Language Processing 7h, covering basic and advanced techniques using NTLK and PyTorch.
- Python Data Visualization 7h, covering basic and advanced visualization with matplotlib, ipywidgets, seaborn, plotly, and bokeh.
- Times Series Analysis for Everyone 6h, covering data pre-processing, visualization, ARIMA, ARCH, and Deep Learning models.
|
|
|
|